In short: most AI roadmaps in Indian pharma fail not on technology but on org design, by aiming the model at the wrong layer of the commercial hierarchy. Name the layer you are targeting, the role that owns the workflow, and the data it runs on, in plain language, and the build-or-buy and technology choices get much easier.
The single most common failure mode of AI roadmaps inside Indian pharmaceutical companies is not that they pick the wrong technology. It is that they pick the wrong layer of the org to deploy the technology against. A model trained at the SKU level is useless to a Brand Manager planning a quarterly campaign. A model that aggregates to a division is useless to a Territory Manager building next cycle's call plan for a specific brand. A demand-forecasting model trained on primary-sales numbers will be wrong about shelf availability in ways the SMSRC Rx data could have predicted three months earlier.
The pattern is not subtle once you see it. The pattern is that the people writing the roadmap and the people running the operation are using different mental models of the org, and the model holds them together poorly. The good news is that the operational model is well-defined, it is widely shared across operating Indian pharma companies, and once a roadmap is written with the operational model explicitly in mind, the conversation gets much more useful very fast.
This piece walks through that operational model: the product hierarchy, the field-force hierarchy, the geography hierarchy, the data layers that live at each, and the kinds of AI questions that are well-formed at each layer versus the kinds that look interesting but turn out not to be.
The product hierarchy
Indian pharma companies organise their portfolio in roughly four layers: cluster or therapy area at the top, division beneath that, brand beneath that, and SKU at the bottom. A cluster might be "cardiology"; a division within it might be "oral antihypertensives"; a brand within that division might be a specific molecule's branded formulation; an SKU is the exact pack, strength, and presentation that gets shipped.
The reason this matters for AI is that every interesting commercial question lives at a specific layer of this hierarchy, and the question is unanswerable at any other layer. "How much of brand X did we sell last month" is a brand-level question. "How much stock did we ship to the central warehouse" is an SKU-level question. "How is our cardiology portfolio performing against the market" is a cluster-level question, and it can only be answered by aggregating IQVIA-class market share data across the relevant brands and reconciling it with our own secondary sales.
An AI workload that produces an answer at the wrong layer of this hierarchy is producing the wrong answer. Most do.
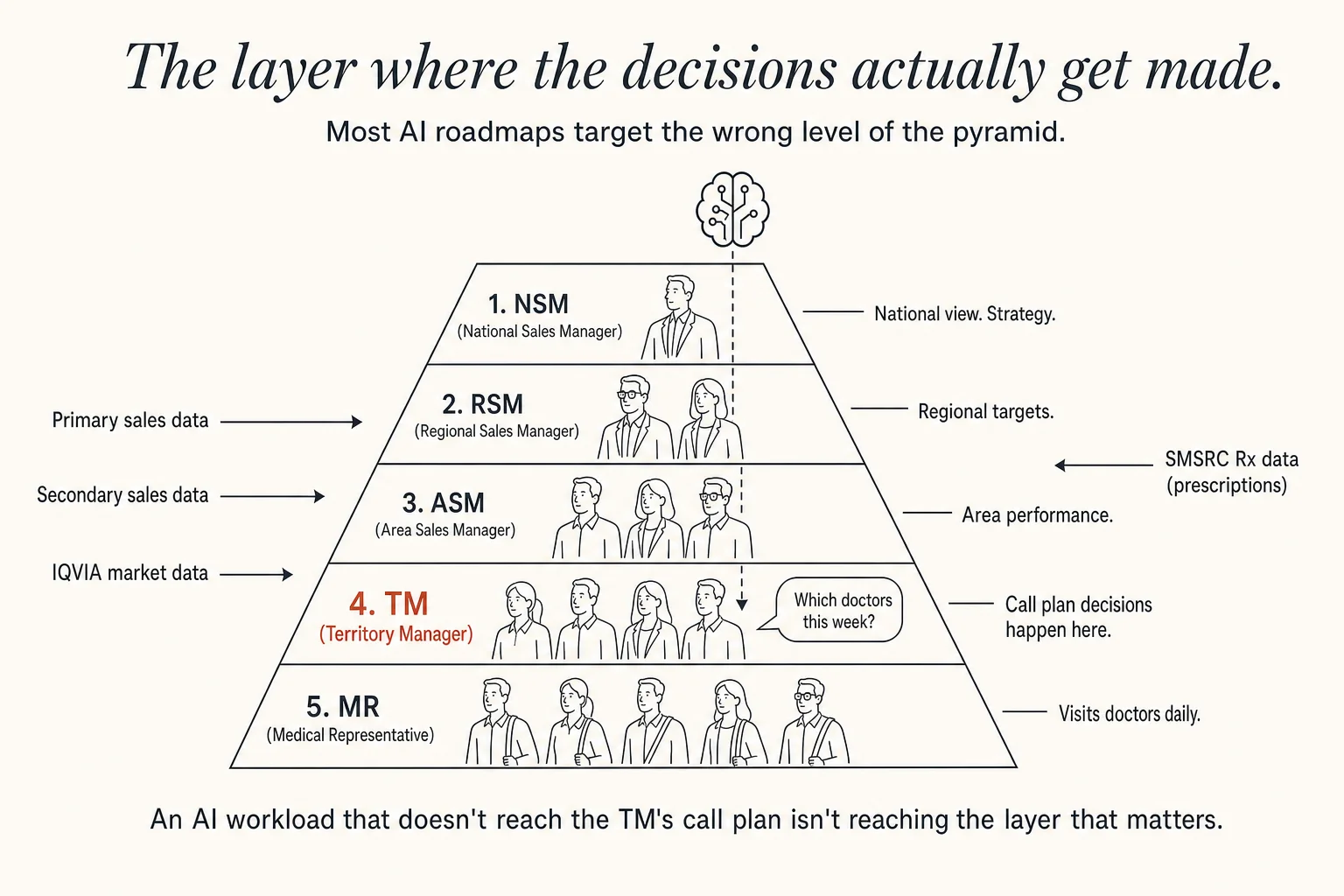
The field-force hierarchy
The reporting pyramid of the in-person sales organisation has a five-rung structure that every Indian pharma reader recognises: National Sales Manager (NSM) at the top; under them, Regional Sales Managers covering large multi-state regions; under each RSM, Area Sales Managers; under each ASM, Territory Managers; and under each TM, the Medical Representatives, the MRs, who actually visit doctors and chemists every working day.
The MR is the only person in this entire pyramid who meets the prescriber. The MR is also, by a wide margin, the most expensive resource the commercial function deploys. Most commercial AI workloads (and most commercial AI vendor pitches) are implicitly trying to make the MR more productive, less expensive, or, in the more honest cases, both. The question that separates a useful AI roadmap from an unhelpful one is whether the roadmap has a clear answer to a specific question: how does this change what the MR does on Monday morning?
If the roadmap cannot answer that question concretely, the workload it is proposing is targeting the wrong layer. A model that produces beautiful aggregate insights at the NSM level changes nothing about Monday morning at the MR level. A dashboard that helps an ASM rank her territories does not, by itself, move a single prescription. The interventions that matter at the MR level are short, concrete, and timed: a specific doctor to detail this week, a specific brand to position against a competitor that gained share last month, a specific chemist to follow up with about an SKU that has been stuck on the shelf.
An AI workload that does not change what the MR does on Monday morning is targeting the wrong layer of the pyramid.
— The test of a useful pharma AI roadmap.
The Brand Manager, on the marketing side of the org, is the other half of this equation. Brand Managers sit at HQ, own one or more brands across the country, and hold the budgets that turn AI pilots into production deployments. The questions they ask are concrete: which territories are under-indexing on Brand X relative to its IQVIA market share, which MRs are over-detailing low-Rx product, which doctors are switchable. Any AI tool that wants a long life inside a commercial function in Indian pharma has to be useful to a Brand Manager and useful to an MR's Monday morning, simultaneously. The two audiences look at different screens and consume different artefacts, but the underlying model has to serve both.
The geography hierarchy
Indian pharma slices the country for sales planning, target-setting, and attribution along a five-level geography: All India → Zone → Region or State → Territory or HQ → City. A territory, often called an HQ (short for "headquarter", confusingly the same word the company uses for its head office), is the unit a single MR covers, give or take a few towns. It is the smallest unit at which most commercial decisions are actually made.
Almost every interesting commercial AI question in Indian pharma is a territory-level attribution problem in disguise. Did secondary-sales movement in HQ X come from the MR's call plan? From a Brand Manager promotion? From a chemist incentive? From a regional market shift the IQVIA layer would have detected? From competitor stock-out? From doctor turnover? The interesting attribution problems happen at the territory level because that is where causes and effects are close enough to disentangle. Aggregate to the zone level and the noise washes out the signal. Disaggregate to the city level and the sample size is too small to be useful.
The teams that get the most out of AI are the teams that have done the unglamorous work of normalising their data to consistent territory definitions across primary sales, secondary sales, IQVIA, and SMSRC. The teams that have not done that work are running attribution analyses on incompatible geographies and convincing themselves of conclusions that do not survive contact with the next month's data.
The data layers
There are four datasets that show up in almost every Indian pharma commercial AI conversation. They are easy to confuse, and confusing them is one of the most expensive errors a roadmap can make.
Primary sales are what the manufacturer ships to stockists. Primary is what the company books as revenue. It is the cleanest dataset the company owns: it is internal, it is daily, and it is reconcilable to the general ledger. It is also, for most demand questions, the least useful of the four. Primary tells you what left the factory; it does not tell you what reached a patient.
Secondary sales are what stockists ship to retailers (chemists). Secondary is what is actually moving through the trade. The catch is that secondary data comes from the stockist's own systems, which means it lags, it is incomplete, and it is contaminated by whatever incentives the stockist had to report or not report a particular movement. Most Indian pharma companies now have decent secondary visibility for their top brands and limited visibility for the long tail.
IQVIA market data (or its equivalent) is the dominant third-party dataset, syndicated, audit-grade, slow to arrive (monthly with a lag), and indispensable. The relevant cuts are Market Share, Rank within therapeutic class, and absolute Market Value, sliced by geography and by SKU. Every Brand Manager review opens with the latest IQVIA numbers; every commercial AI workload eventually has to reconcile against them. A workload that improves an internal metric while moving IQVIA in the wrong direction is dead on arrival, regardless of how technically interesting it is.
SMSRC Rx data is the prescription audit. It audits a panel of doctors and estimates, brand by brand and geography by geography, how many prescriptions are being written. It is the closest dataset Indian pharma has to a real-time measurement of what doctors are actually doing. The crucial thing to understand is that SMSRC Rx and IQVIA secondary measure different things: one says what was prescribed; the other says what was moved through chemists. They diverge regularly, and the size and direction of the divergence is itself a signal worth modelling.
The AI workloads that mature into production are the ones that respect all four datasets. The ones that fail tend to be the ones that picked a single dataset because it was cleanest and then over-fit a model to it.
Putting the layers together
The test of a good AI roadmap inside an Indian pharma commercial function is whether, for each proposed workload, it can answer three questions cleanly:
First, which layer of the product hierarchy is this targeting? Cluster, division, brand, or SKU. If the proposed workload spans layers ambiguously, it is going to produce results at a granularity nobody can act on.
Second, which layer of the field-force hierarchy is this designed to serve? NSM, RSM, ASM, TM, or MR. And, separately, is there a Brand Manager whose budget will sponsor this, and whose monthly review this will land in. If both answers are clear, the workload has a chance of surviving past the pilot stage. If either answer is fuzzy, it will not.
Third, which combination of the four data layers does this rely on, and how does it reconcile when the layers disagree? A workload that uses only primary sales is fast and clean and probably wrong. A workload that triangulates primary, secondary, IQVIA, and SMSRC against a consistent territory definition is slow to build and likely to be useful.
The roadmaps we have seen work best are not the ones that propose the most ambitious AI. They are the ones that name the layer they are targeting, the role they are serving, and the data they are reconciling, in plain language, at the start of every conversation. The technology choices, surprisingly, become much easier once those three questions are answered.
Why this conversation matters now
The point of working through the hierarchies in this much detail is that the conversations that close the gap between proof-of-concept and production AI inside Indian pharma are conversations between people who already speak this language. The Brand Manager who wants to attribute secondary-sales movement to a specific MR's intervention does not need an AI vendor to explain what an SKU is. The sales-excellence lead who is evaluating a model for call-plan optimisation does not need a primer on what RCPA is.
The conversations that matter happen between peers, fast, in vocabulary both sides already share. AI for Pharma is being convened so those conversations happen in a single room, deliberately, on a schedule. The vocabulary in this essay is the working vocabulary of the room. If you recognised yourself in any of these paragraphs, that is who the consortium is being built for.
Applications are open.